
by Peter Hora
 Big Data is a popular buzzword but when it’s actually used in everyday tasks, practical questions about data governance, no different from those being asked of other data storage technologies, arise.
Big Data is a popular buzzword but when it’s actually used in everyday tasks, practical questions about data governance, no different from those being asked of other data storage technologies, arise.
When you read about a new technology it can often sound like the answer to everything. But then mundane reality comes along and things are seen to be far less flashy and much more messy than they first appeared. This is true too for Hadoop-related technologies (a.k.a. Big Data) which are in their core nothing more than a file system where you can store a really large number of zeroes and ones.
Imagine the following situation in your department: you receive an announcement from your IT guy – “Dear colleagues, from now on feel free to upload anything onto our shared drive, the cost of storage is close to nothing so knock yourselves out”. The data-loving crowd would literally dump anything they could lay their hands on in there, following the simple reasoning, “What if this data set is useful one day”.
Sanity check – can you, right now, find or discover any useful data on your current shared drives? And do you think you’d be able to if the shared drive size wasn’t measured in terabytes, but petabytes or even exabytes (1 billion gigabytes)?

Storing data in traditional relational databases you need to define tables, columns and the relationships between them. You don’t need to bother with such details in Big Data technologies. Every user can do that for their own context or doesn’t need to do it at all. The result is far less structure and therefore far less descriptive information about data sets (re: metadata). So metadata management, security and governance are in fact becoming more challenging than they used to be with the good old-fashioned relational databases.
As a vendor of a data governance support tool we love to address this type of a challenge. When you strip down all the hype and focus on the core of the problem – Big Data (Hadoop and derived platforms like Cloudier, Hortwonworks, Teradata Aster …) are no different from any other data storage platform. Just with less metadata. So this is how to deal with it:

Using a Hadoop API we extract the information that’s available about the stored content – file names, folders, timestamps, user names … and publish it in an easy-to-search and understandable wiki-style format so users can work with it in everyday use cases like the following:
- Information worker
- discovery – when you have a question you can browse through the catalogues of existing data to discover where the answers are.
- request – a user can request access to or extracts from existing data-sets, reusing outputs.
- Data steward
- governance – documenting data-sets, establishing ownership of them and linking them to other information assets is easy.
- data quality – stewards can assign data quality labels to data-sets in order to avoid the accidental misuse of data.
- Hadoop Administrator
- monitoring – the administrator can keep a note of new folders / files and check that the minimum data-set descriptions were filed – if not, he/she identifies the user and can request additional info.
- impact analysis – it’s important and easy to check if a data-set is used by any report or project before it is purged.
Here’s an example of how the documentation of a data-set stored in HDFS is displayed in our DG support tool. You can also see how its relationships to other information assets are displayed:

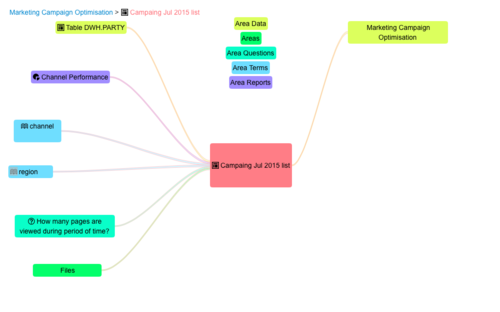
Big data is becoming an integral part of the information landscape of today’s enterprise environment. You might be using new prefixes to enumerate the storage size, but everyday tasks of data governance are no different to those with any other data storage platform.