
In a very short time, Apache Hadoop has become one of the most popular platforms for storing and managing big data. To make the data stored in Hadoop accessible for everyone and for every reporting tool, many SQL‐on‐Hadoop engines have become available, making it possible to access big data stored in Hadoop files with good old SQL. But where do we stand with these products today?
Why is Hadoop Successful?
Hadoop owes its success to its high data storage and processing scalability, low price/performance ratio, high performance, high availability, high schema flexibility, and its capability to handle all types of data.
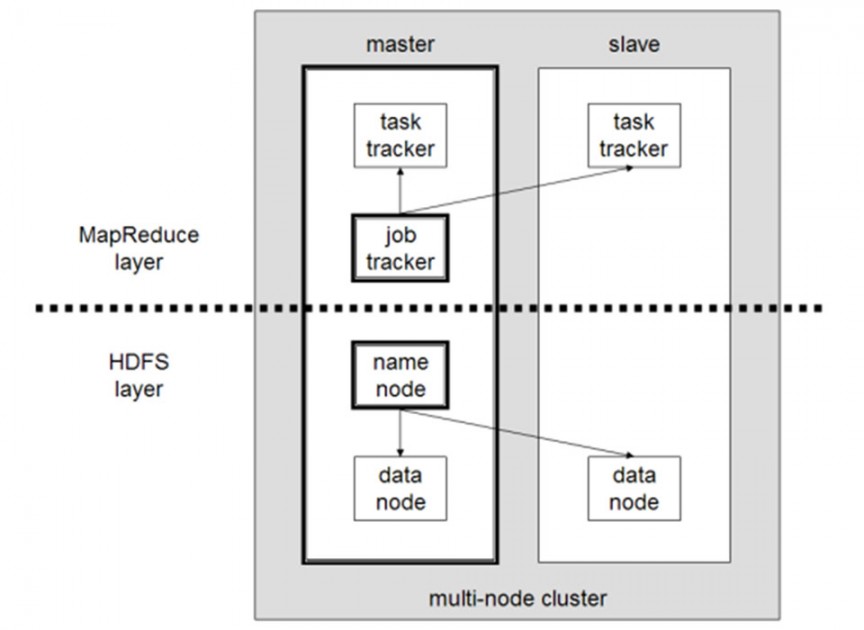
Hadoop APIs, such as HDFS, MapReduce, and HBase, offer APIs for accessing data. They allow applications to be developed for the simplest queries to the most complex forms of analytics. Unfortunately, these APIs are quite complex. They require expertise in Java programming (or similar languages) and in‐depth knowledge of how to parallelize query processing efficiently. The downsides of these interfaces are:
- Small target audience: These interfaces make Hadoop unsuitable for most of the business analysts, data scientists, and other non‐technical users, who typically don’t have such skills. The consequence is that the potential analytical power of MapReduce is limited to a happy few.
- Low productivity: Due to their technical interfaces, the productivity of developing in Hadoop APIs is not high (compared to, for example, developing in SQL) and analysis can be time‐consuming as well.
- Limited tool support: Many tools for reporting and analytics don’t support the MapReduce and HBase interfaces and can therefore not be used for developing reports on big data. Most of them only support SQL. If such tools must be used, the only option is to copy all the data to a SQL database server. This is a costly and time‐consuming exercise.
Combining Hadoop with SQL
What is needed, is a programming interface or language that retains HDFS’s performance and scalability, offers high productivity and maintainability, is known to non‐technical users, and can be used by many reporting and analytical tools. The obvious choice is the well known old warhorse SQL.
SQL is a high‐level, declarative, and standardized database language, it’s familiar to countless BI specialists, it’s supported by almost all reporting and analytical tools, and has proven its worth over and over again. To offer SQL on Hadoop, SQL query engines are needed that can query and manipulate data stored in HDFS or HBase. Such products are called SQL‐on‐Hadoop engines.
The first SQL‐on‐Hadoop engine that was introduced a few years ago is called Apache Hive. Hive offers a SQL‐like interface to query data, manipulate data, and to create tables. It supports a dialect of SQL called HiveQL. In 2013, the market started to understand the importance and business value of a SQL interface. The result was that many more SQL on‐Hadoop engines were announced and introduced. Here are just a few of the many SQL‐on‐Hadoop engines available: Apache Drill and Hive, CitusDB, Cloudera Impala, Hadapt, HP Vertica, InfiniDB, JethroData, Pivotal HAWQ, Spark SQL, and SpliceMachine.
Use Cases of SQL-on-Hadoop
On the outside, most of the SQL‐on‐Hadoop engines look alike. They all support some SQL‐dialect that can be invoked through ODBC or JDBC. Internally, they can be very different. The differences stem from the purpose for which they have been designed. Here are some potential use cases for which they may have been designed:
- batch‐oriented query environment (data mining)
- interactive query environment (OLAP, self‐service BI, data visualization)
- point‐queries (retrieving and manipulating individual objects)
- investigative analytics (data science)
- operational intelligence (real‐time analytics)
- transactional (production systems)
Note that this is not very different from the market of SQL database servers itself. For example, there are products optimized for a transactional workload while others exceed in complex forms of analytics.
Maturity of SQL-on-Hadoop
Besides the differences with respect to their use cases, they also differ in their level of maturity. This is especially relevant to their query optimizers. Efficient query optimizers that are able to come up with the perfect processing strategy for every query are not born in development labs. They need many “hours in the saddle.” It’s when an optimizer is used over and over again in all kinds of situations, that the developers start to get a feeling how to improve and optimize it. This process may take a few years. Some of the SQLon‐ Hadoop engines are still young and still have to proof themselves in large scale, complex, and multi‐user environments.
Summary
That many organizations interested in big data and Hadoop will eventually deploy one or more SQL‐on‐Hadoop engines is evident. This means they have to select one of these products, and that’s not a trivial task. Organizations must understand their use cases. Also, they have to be aware of the fact that this is still an evolving market, so they must keep open an alternative route. They should not tie themselves to one solution that may cause problems later on.
Nowadays, self‐service BI is too much like tinkering with a hot rod. With an integrated BI platform, it becomes like buying a car: two minutes after paying for it the customer is on the road.
About the Author
 Rick F. van der Lans is an independent analyst, consultant, author, and lecturer specialising in data warehousing, business intelligence, data virtualisation, and database technology. He is Managing Director of R20/Consultancy based in The Netherlands, and has advised many large companies worldwide on defining their business intelligence architectures. His popular IT books have been translated into many languages and have sold over 100,000 copies. Rick writes for the TechTarget and B‐eye‐Network. For the last 25 years, he has been presenting professionally around the globe and at international events. In 2012, Rick published a new book entitled “Data Virtualization for Business Intelligence Systems“.
Rick F. van der Lans is an independent analyst, consultant, author, and lecturer specialising in data warehousing, business intelligence, data virtualisation, and database technology. He is Managing Director of R20/Consultancy based in The Netherlands, and has advised many large companies worldwide on defining their business intelligence architectures. His popular IT books have been translated into many languages and have sold over 100,000 copies. Rick writes for the TechTarget and B‐eye‐Network. For the last 25 years, he has been presenting professionally around the globe and at international events. In 2012, Rick published a new book entitled “Data Virtualization for Business Intelligence Systems“.
Contact Info: Rick F. van der Lans, R20/Consultancy , E-Mail rick@r20.nl , Twitter @rick_vanderlans
This article is derived by permission from the whitepaper by Rick van der Lans SQL‐on‐Hadoop Engines Explained, published by MapR Technologies, May 2014.
See http://info.mapr.com/wp‐ sql‐ on‐ hadoop‐ engines‐ explained.html?cid=resources