

User story splitting is an established practice on agile delivery teams. But in my experience, it’s really difficult to do well. In this article I’ve pulled together everything I’ve learned about story splitting. It’s a long article, so you might want to make yourself a nice, hot cup of tea before you get started.
 Tony Heap, Business Analyst Designer, its-all-design.com and Equal Experts
Tony Heap, Business Analyst Designer, its-all-design.com and Equal Experts
Tony will be speaking at the 10th annual Business Analysis Conference Europe, 24-26 September 2018 in London. He will be speaking on the topic, ‘Options Engineering‘.
This article was previously published here.
What Are User Stories?
I think of a user story as a unit of scope, a unit of delivery.
Importantly, a user story delivers something useful (or valuable) to somebody. In an IT context, this is usually the person using the system (although occasionally it’s a different stakeholder who wants to restrict the user in some way, such as protecting the system from unauthorised access).
For this reason, user stories are generally described from a user perspective with the “As a…I can…So that…” format, forcing the delivery team to stay focused on what the user is trying achieve, and why.
Note that the term “user story” is used in two subtly different ways. As mentioned above, I generally use it to mean the units of scope to be delivered, as in “we’ve delivered stories X, Y and Z in this sprint”. But it’s also commonly used to refer to the descriptions of those units of scope – the “As a…I can…So that…” statements – the deliberately non-specific descriptions that are a promise to have a conversation. In this article, I use the term user story to refer to the units of scope themselves, and the term user story description to refer to the descriptions of those units of scope. When I talk about story splitting, I am talking about splitting the scope items into smaller scope items, not splitting the descriptions of the scope items into smaller descriptions!
Properties of User Stories and INVEST
According to the INVEST mnemonic, a user story should be:
• Independent – not dependent on other stories
• Negotiable – not cast in stone; up for discussion
• Valuable – to some stakeholder (usually the end user)
• Estimatable – unambiguous enough for the delivery team to have a good idea how big it is
• Small – small enough to deliver several stories in a single sprint/iteration
• Testable – if it can’t be tested, it clearly isn’t doing anything for any user
In my experience, it’s not always as simple as this – splitting stories so they are “small enough” often introduces dependencies between stories, and the individual stories are often not valuable on their own – they only become valuable once a certain number of related stories have been delivered. So I tend to treat the INVEST properties as guidelines rather than incontrovertible laws. Some of the properties apply more to epics (large stories) and others more to small stories.
My one rule for all stories is that, whatever size they are, they must deliver something that is user-visible. This goes hand in hand with vertical story slicing, more of which later.
Why Split Stories?
The most obvious reason to split stories is to break them into bite-sized chunks – small enough to deliver several of them in a single sprint. How do you eat an elephant? One piece at a time.
There is another reason which, in my view, is equally (if not more) important, and probably less well understood. It’s to do with the Pareto Principle – also known as the 80:20 rule.
The 80:20 rule basically says that you can get 80% of the job done in 20% of the time. Put another way, it takes 80% of the time to finish off the last 20% of the job. It reflects the fact that most jobs involve a number of “fiddly bits” that take a long time to do, so whilst it feels like you’re almost there, actually you’re not.
In the domain of software delivery, the last 20% of the work usually represents the alternative flows – unusual, unexpected or error conditions. And often, a fair number of these high-effort “fiddly bits” are also low value – they deal with esoteric scenarios that crop up once in a blue moon.
Splitting stories provides me with an opportunity to separate the high-value stuff from the low-value (high-effort) stuff. Once a story is split, and the sub-stories are placed on the product backlog, the low-value stories naturally filter to the bottom of the backlog during re-prioritisation sessions.
The beauty of doing it this way is that I never need to have an argument with my Product Owner about whether a certain edge case should be handled or not. I can put it on the backlog and let them prioritise it accordingly. And sooner or later, the project sponsor will call time on the project and the low-value stuff will remain forever undelivered (also known as “trimming the tail”).
When splitting stories, I try to keep both of these objectives in mind: make them small, and split out the low-value stuff.
Story Hierarchies and Epics
It’s common to refer to large stories as epics.
My experience is that it might be necessary to split an epic (a large story) many times before I get to the point of having stories that are “just the right size” for the development team. It depends on how big the original (epic) story is, how small my development team want the stories, and how many splits I need to separate out all the low-value stuff.
So I see story splitting as an iterative activity – I split a large story into two or more sub-stories, and then I might further split each of the sub-stories into sub-sub-stories, and so on until each story is small enough. That’s not to say I do all my story splitting up front. I only split a story at the appropriate time, more of which later. The key point is that ultimately, eventually, there is a hierarchy of stories, and the hierarchy can be many layers deep, and not all branches are the same depth. For example:

Some teams/methods/tools define a taxonomy for stories, with a fixed number of levels in the hierarchy. For example:
• Level 1: Epic
• Level 2: Feature
• Level 3: Capability
• Level 4: Story
I don’t like this approach. My experience is that story hierarchies don’t always fall neatly into a fixed number of levels, and thus the team can spend too much time wondering, “is this story an epic or is it only a feature?” when actually it doesn’t really matter.
I prefer to follow Mike Cohn’s advice: everything is a story. If I split a story I get…some stories. If I have a story that feels like it’s large enough to warrant splitting, or if I’ve already split it, I refer to it as an epic. But it’s still a story.
An epic is a user story that feels like it’s large enough to warrant splitting, or has already been split
Importantly, and as mentioned above, however large or small a story is, It still delivers something that’s visible to a user and useful to a stakeholder, so I can still write its summary in the “As a… I can… So that…” format.
How Far To Go
How do you know when your stories are “small enough”?
My experience is that it depends on your delivery team, and on your sprint/increment duration. Recently I’ve been working in teams with 2 week sprints, and the developers like the stories to be small enough to deliver between 8 and 12 stories in each sprint. They want to be able to deliver a single story in a few days at most.
Smaller stories improve productivity and motivation – team members can focus on one small thing at a time and get it done quickly – going home each day with something either done or with the end in sight. They also make for better resource planning – the stories can be divided up amongst team members more easily, and it’s easier to work around team member absence/leave.
Getting stories this small generally means breaking them down beyond the point where they can be considered either independent or (individually) valuable to the end user – the user value only comes when a number of related, co-dependent stories are delivered. As I mentioned above, it’s difficult to get a story that has all the INVEST properties at the same time.
On every team I have worked in, we have found the ideal size for our stories by trial and error. Here’s how it works. I prepare a few stories – to the point of drafting BDD scenarios and, if appropriate, creating some wireframes or an HTML prototype. I arrange a Three Amigos session to go through the stories with the team. For each story, before I ask them to estimate it, I will ask them if they think it’s small enough. If not, we work out a way to split it. After a few such sessions, I get a feel for what is “the right size” for a story, and usually go into the Three Amigos with appropriately sized stories. Ironically, as the team matures, and productivity increases, they sometimes decide that now my stories are too small, and we end up combining stories that I had previously split!
When to Split Stories
The simple answer to this is: just in time.
I need just enough bite-sized stories to feed into the next sprint/increment. Or if I’m doing Kanban, I need just enough bite-sized stories to keep all my developers busy.
I analyse stories in priority order, including splitting. So if a story is low priority, it’s likely to still be quite large, because I haven’t done any analysis on it yet.
So I would expect the stories near the top of my product backlog to be small and the stories near the bottom to be larger. My backlog ought to look something like this:
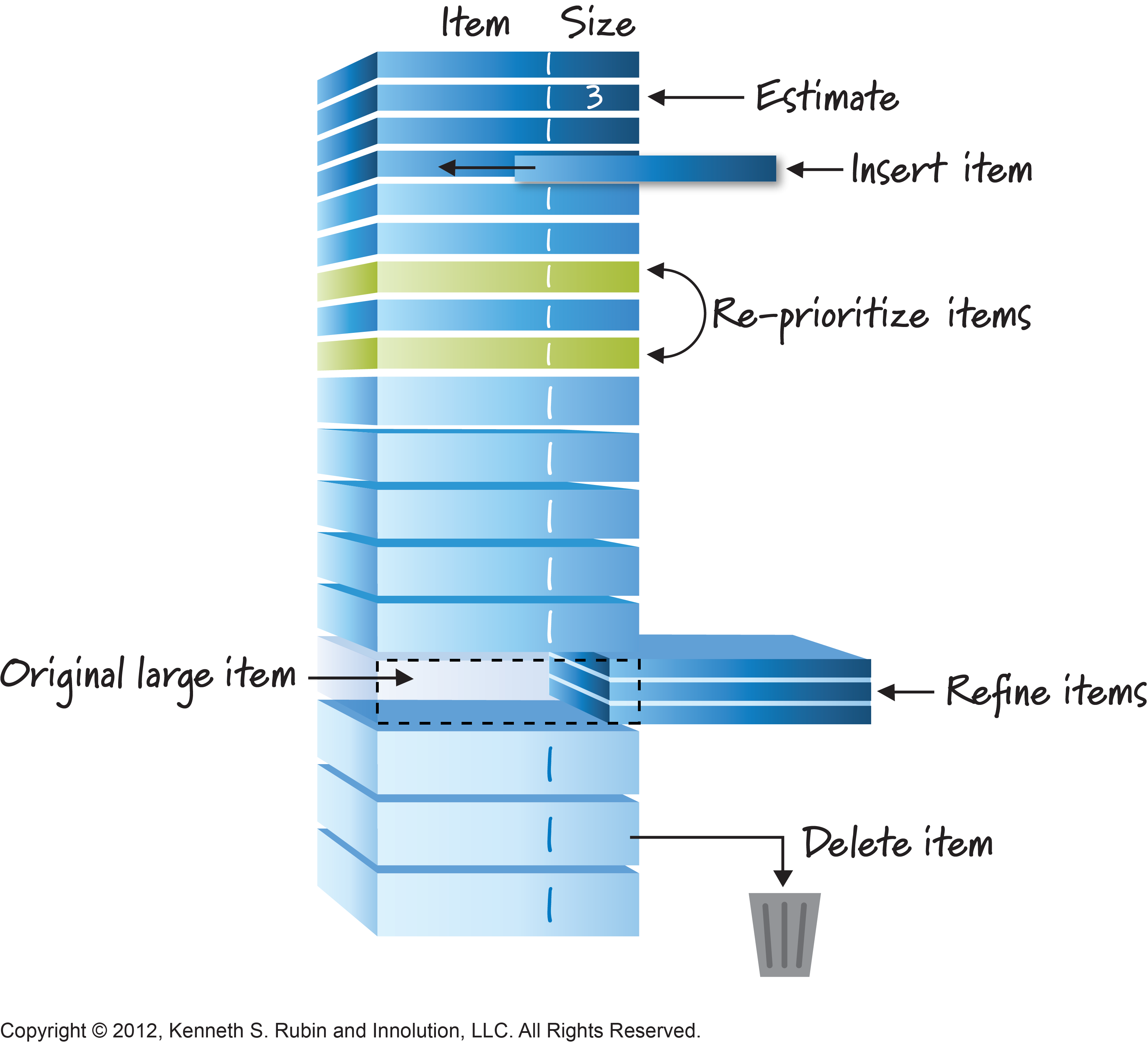
(thanks to Ken Rubin for that diagram, by the way)
Actually that’s not quite true. Remember, one of my motivations for splitting stories is to split out low value bits and have them filter down the backlog. Every time I split a story, it’s important that I get the sub-stories re-prioritised with respect to the rest of the backlog to make sure this filtering effect actually happens. So there might be some small stories further down my backlog too – these are low priority bits of stories I have already split.
Do Some Analysis First
Before I can split a story, I first need to do some analysis work to understand that story. Otherwise, I don’t know enough about it to decide how to split it.
I actually have a fairly structured process for doing this analysis work. In fact, it’s so structured, I’ve given it a name: Business Analysis Designer Method (BADM). Here’s a diagram that summarises the process:
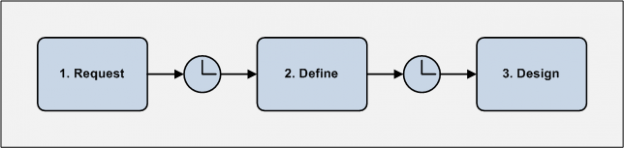
Don’t be fooled. BADM is not a waterfall method. Rather, each phase is executed in turn on individual stories to be delivered.
In the “Request” phase, a story is requested, but at that stage we don’t really have any idea what the objective is, or what would be the best way to achieve it.
In the “Define” phase, the BA does the work to identify the stakeholders, understand the opportunity space, suggest options to achieve it and agree the preferred option with the Product Owner and other stakeholders. The BA also splits the story into priority-oriented sub-stories if appropriate.
The sub-stories are added to the product backlog and re-prioritised, and the method iterates on the sub-stories until they are “small enough”. Finally, in the “Design” phase, the BA does the more detailed analysis that’s needed for delivery – acceptance criteria and/or behaviour scenarios (aka use cases), wireframes (or UI prototypes), data models and so on.
I’m not suggesting that everyone should use BADM, but it’s definitely a good idea to spend some time understanding the scope of a story before splitting it.
Vertical Story Slicing
As I mentioned above, I have only one golden rule for splitting stories. When I split a story, each sub-story must deliver something user-visible. When I say “user visible”, I mean observable at one of the system’s user or system interfaces (a user can, of course, be another system).
Here’s the problem. When presented with a user story that is “too big”, a development team’s first instinct is usually to carve it up along architectural lines. One developer does the database schema changes. Another codes the middle tier business or controller logic. A third makes the user interface changes. The story is sliced “horizontally” through the architectural tiers.
There are a few problems with this approach:
- There is no perceivable user benefit until all related stories are complete
- We can’t test the system until all related stories are complete
- We don’t uncover any architectural issues until all three stories are complete
- We miss the opportunity to split out the high-effort, low-value “fiddly bits” to be done later
The preferred approach, therefore, is to slice stories “vertically”, with each story delivering a thin slice of change through each (relevant) architectural tier. That way, we have some (small) user benefit after each story, we can test each story, and we can identify any architectural issues sooner.
When slicing stories vertically, note that:
• Some stories might only affect the presentation tier (for example, a change to a field or button label) – as opposed to slicing through all the architectural tiers.
• Some stories deliver change to system interfaces, not user interfaces. They are still “user visible” but in this case the user of the system is another system, not a human user.
• Some stories are non-functional e.g. performance or security enhancements. This is OK – an improvement in response time is user-visible.
• Some stories are time-triggered (batch) processes that affect system state (i.e. they change the data in the database) but aren’t user visible through any user or system interface at the time when they occur (although their effect is seen later, next time the data is queried). This is a special exception to the “user visible” rule – the user is allowed to wear X-ray specs to observe the system state changing! Likewise, the story is testable, but the tester needs to poke about in the database to see the change.
Also note that once a story is “small enough”, the development team might still decide to split it down into “horizontal” parts – database changes, UI changes and so on. This is perfectly fine – this is splitting a story into tasks (specifically, development tasks) and some teams do it during sprint planning to help them estimate the effort for the story and/or divide the work amongst team members. The difference is that it is understood and expected that the story is not done (or even ready for testing) until all the development tasks have completed. The unit of scope (or delivery) is the story, not the task.
I’ve only really provided a summary of vertical story slicing here. There are plenty of good articles that go into more detail, such as this one by Ned Kremic.
User Goal Decomposition
As mentioned above, vertical story slicing is all about splitting stories down into smaller and smaller user-visible changes. Each story, however small, delivers something valuable to the user, it helps them achieve some goal.
Another way to look at vertical story slicing is user goal decomposition. By splitting a story, I am splitting the user goal into sub-goals.
Here’s an example to illustrate. Let’s say I have a user story as follows:
Registration
As an owner of unwanted stuff
I can register for the online auction website
So that I can sell my unwanted stuff
The user goal for this story is register for the online auction website. The benefit is sell my stuff. But this story is too big, and I want to split it. So I split it like this:
Registration – Enter Details
As an owner of unwanted stuff
I can enter my registration details (name, email address etc.)
So that I can register for the online auction website
Registration – Submit Details
As an owner of unwanted stuff
I can submit my registration details
So that I can register for the online auction website
I have created two sub-goals – enter my registration details and submit my registration details. In this instance, the latter is dependent on the former – I have to enter my details before I can submit them. More importantly, once I have achieved both sub-goals, I have achieved my original goal – register for the online auction website.
I could then go on to split the sub-stories even further, until my stories are “small enough”. I would end up with a hierarchy of stories and also a hierarchy of goals.
Notice in particular that the “so that” statement (the benefit) of the sub-stories is the “I can” statement (the goal) of the original story. Put another way, the benefit is really a higher-level goal. Once I realised this, it became much easier to write the “so that” part of my sub-stories – they are simply the “I can” part of the parent story (i.e. the parent goal).
It would almost be better to explain the user story description template like this:
As a <user>
I can <goal>
So that <higher level goal>
It also follows that the benefit of my original goal – sell my stuff – is really just a higher level goal. Which in turn is a sub-goal of an even higher level goal to make some cash. Which in turn is a sub-goal of buy food, then feed my family, then keep my family alive, and so on until you either end up in an infinite regression of parent goals or lose yourself in philosophical questions like “why are we even here”?
Three Named Goal Levels
With a potentially infinite hierarchy of user goals (both upwards and downwards), there’s a real risk of getting lost.
In his most excellent book Writing Effective Use Cases, Alistair Cockburn does a good job of explaining goal decomposition, and in particular, he sets down a metaphorical anchor by identifying and naming three specific goal levels. In his book he was talking about use cases, but the theory applies equally well to user stories.
The most important goal level is user goal level, also known as sea level, or blue. At this level, a single user achieves (or fails to achieve) a single goal in a single sitting, for example “list an item for sale”. You can check whether a goal is a user goal by asking whether or not it passes the “coffee break test”: could you reasonably take a coffee break after achieving the goal?
Above user goal level is summary level, also known as cloud/kite level or white. Summary level user goals are collections of related user goals, for example “manage widgets” breaks down into “create widget”, “view widget”, “edit widget” and “delete widget”.
Below user goal level is subfunction level, also known as underwater level or indigo. Subfunction level goals are not useful to the user in their own right – they are steps towards achieving the user level goal, for example “enter item name” is a sub-goal of “list an item for sale”. “Log in” is a common subfunction level goal – logging in doesn’t achieve anything in its own right, it’s always a precursor to achieving something else.
Cockburn chose the sea-level / cloud / underwater metaphor quite deliberately. The sky goes up a long way and the sea goes down a long way, and there are correspondingly many nested levels of cloud level goals and many nested levels of underwater goals (and there are many shades of white and many shades of indigo). But there is only one sea level – a user goal is a user goal and should be very clear to define.
Just to be clear, I’m not advocating a three-level fixed hierarchy of user stories – I argued against that earlier on. I’m just saying that recognising where the sea-level is in my user story hierarchy can be useful for keeping track of delivering user value.
A Sequence for Splitting Stories
There are many tried-and-tested ways to vertically slice a story. Over the years I’ve noticed that I tend to apply the various techniques in a specific sequence. Some techniques apply more to larger stories whereas others become more relevant once the stories get smaller.
So I’m going to present the various techniques in the order in which I normally apply them. Note that this isn’t a hard-and-fast rule. For a given story, not all techniques will apply, and not necessarily in the same order. I might also use a certain technique more than once.
Here we go…
Technique 1: Split Out NFRs
The first thing that I think about doing for any given large story is to split it into two parts – one part to deliver the function itself and another part to deliver the NFRs (non-functional requirements) on that function.
The key objective of this split is to get the team focussed on delivering the functions and not being distracted by the NFRs. This is especially important early on in a project, where there are lot of unanswered architectural questions. Getting them all answered up front can really slow things down.
Here’s a list of the types of NFR you can consider deferring to focus on functionality:
- Performance – defer making it fast
- Scalability – defer making it support large numbers of concurrent users or large volumes of data
- Concurrency – defer making it support more than one concurrent user (data locking, race conditions etc.)
- Availability – defer making it highly available and fault tolerant
- Security – defer protecting it from attack
- Usability/accessibility – defer making it easy to use (for everyone)
- UX – defer making it look nice
- Cross browser / platform – defer making it work for a variety of client devices
- Internationalisation – defer support for multiple languages / local conventions
All of these things have the capacity to distract the team from delivering something simple that (just about) works functionality, and which can subsequently be built upon (refactored) to deliver the various NFRs in due course. Splitting out the NFRs says to the team “we will look at the NFRs, but don’t worry about them for now”. It might be that we can even deliver an MVP without looking (formally) at all the NFRs. It depends on whether my MVP will go public or whether it will be a private beta with a limited, well-known user group.
I usually split the NFRs out initially as a single story, called something like “Project X NFRs” or maybe “Feature X NFRs”. In due course, when we do look at the NFRs in more detail, I am likely to split the NFRs story down further into individual NFR categories (performance, availability, security etc.) and bite them off one by one (in stricy priority order, of course).
Eventually, we might incorporate the relevant NFRs into the “definition of done” for every subsequent story. But that’s another article.
Exactly when “in due course” happens is a fine balance. We don’t want to get weighed down in architecture too early, but we don’t want to leave it too late either, or we might incur too much technical debt, plus we’d be carrying architectural risk. As ever, judgement comes with experience on this one, and there’s never a simple answer – over the years, I have seen as many over-engineered systems as I have seen under-engineered ones.
Technique 2: Split By User Interface Channel
This is a special case of splitting out NFRs. One of the NFRs I mentioned above was cross-browser/platform support. If my system has a user interface, and the intention is to support multiple channels (e.g. desktop, tablet, mobile) or multiple platforms (e.g. Windows, Mac, iOS, Android, various flavours of smart TV) then it sometimes makes sense to focus on one of these channels/platforms first. The obvious thing to do is to pick the channel/platform that we think the majority of our users have.
But as with the other NFRs, it’s a fine balance – at what point in the project does it become prudent to start thinking about other platforms? Is it easier to bake it in sooner, when there are only a few screens to rework, or later so that the team can progress faster for longer? Of course, there’s no right answer – it depends on the circumstances.
Some projects I have worked on have come with a corporate (or government) standard UI framework, which is already designed to be responsive (i.e. works on multiple platforms/devices). Obviously, it makes sense to use the standard framework from the start, assuming it’s relatively stable and doesn’t add too much overhead or learning curve. Even if we do choose to do this, we might still choose to defer formal cross-platform compliance initially. There’s a subtle difference here – by deferring formal compliance, we’re saying that we’re not going to test the system cross-platform yet. Cross-platform testing can be very labour intensive, and is often better done once, shortly before a release, rather than piecemeal on every single story. Our testers can focus on functional testing for now, and we can progress more quickly.
Technique 3: Split By User Type
Some stories serve a diverse community of users. I’m not talking so much about internationalisation here, I’m thinking of categories of users.
For example, on a recent project, our users split out into the following categories:
- Users based in the UK
- Users based in the EU (but outside the UK)
- Users based outside the EU (aka “third country” users)
Don’t get me started on Brexit, that’s another story (ho ho), but the point is that the functionality was different for each of these three categories. UK users had to register by one method, EU users by another, and third country users by yet another.
So we decided to focus on UK users first. And then we discovered another split:
- UK individuals
- UK organisations
Again, the functionality was different for each of these categories. So we decided to focus on UK organisations first. And then we discovered yet another split:
- UK incorporated companies
- UK unincorporated companies
- UK partnerships
Believe it or not, the rules for registration were yet again different for these sub-categories. We focussed on UK incorporated companies first and delivered a full registration journey for them (although we split the registration story down further using other techniques described later). Then we started adding in the other user types, in business priority order. Back to Brexit again – if the UK exits the EU any time soon, we won’t be distinguishing between EU or third country users, so we put the EU users lower down the priority list.
In the end, we broke our user community down into around 15 user types, with around 8 unique user journeys for registration. Delivering the functionality for the first user type was lots of work. Each extra user type we added got easier and easier. But if we had tried to do them all at once I think the task would have been insurmountable.
Technique 4: Split Summary Goals Into User Goals
So far, we’ve split out various NFRs so we can focus on functionality first, and then we’ve split by user type so we can focus in on delivering something for a single user group.
In the next split, we return to the concept of “three named goal levels” discussed earlier. Specifically, we’re looking to split our story into individual user goals (“sea level” goals) that pass the “coffee break test” – they can be achieved by a single user in a single sitting, and completion can be rewarded by a coffee break.
A very common example is to split a data maintenance story into its CRUD components. So for example:
Maintain widgets
becomes
Create widget
View widget
Update widget
Delete widget
Another common example is a story that involves multiple actors. For example:
As a blogger I can publish my article
Might become:
As a blogger I can request to publish my article
As an editor I can approve an article for publication
And there are countless other flavours of summary level goals that can be split down into user goals.
It often appears that the sub-stories follow a logical sequence. You have to be able to create a widget before you can view it, and you probably want to view a widget before you either update it or delete it. You have to request an article to be published before it can be approved. But that doesn’t necessarily mean the stories have to be delivered in sequential order. It’s perfectly possible to create widgets through the back door (by direct database load), so if viewing widgets is the highest value sub-story, it’s possible to do that first.
Technique 5: Split By Scenario / Flow
By now, our stories are at user goal level – they can be achieved by a single user in a single sitting.
And on a good day, things would go well for our user. They would perform actions and enter data and achieve their goal. This is what we call the happy path scenario. There might be many ways of achieving the goal, so there might be multiple happy paths.
But things might not go so well. They might enter invalid data, or they might perform inappropriate actions, or they might not find the data they are searching for, and they might not achieve their goal. There are any ways in which things might go wrong for them, and we call these alternative flows.
Rather than trying to deliver all the possible happy path and alternative flow scenarios in a single story, we can break the story down by scenario.
The first sub-story would deliver the most common or obvious happy path scenario. Further sub-stories would deliver other happy paths and the various alternative flows.
For example,
Create widget
might become
Create widget – success
Create widget – mandatory fields not completed
Create widget – widget name already exists
Another example:
Sign in
might become
Sign in – success
Sign in – invalid sign in details
Sign in – failed three times (lock account)
Sign in – account locked
A key point here is that some of the alternative flows might be lower priority. For example, dealing with an invalid user ID or password is high priority, but locking the account after three failed attempts might not be.
It’s not always obvious what all the alternative flows are for a given user level story. To find them, it’s a really good idea to write out the individual steps for the main happy path scenario. For example:
- User requests to sign in
- System asks the user for their sign in details (user ID and password)
- User enters sign in details
- System verifies that the sign in details are valid for an existing account
- System verifies that the account is not locked
- System signs the user in and displays the home page
Step 4 begs the question: what if the sign in details are not valid? We have found an alternative flow.
Step 5 begs the question: what if the account is locked? We have found another alternative flow.
If you want to become a black-belt at splitting out alternative flows, you should definitely read Writing Effective Use Cases by Alistair Cockburn.
Technique 6: Bronze-Plated Flow Versus Gold-Plated Flow
In technique 5, I split my story into individual flows – happy path and alternative flows. It’s likely that we will focus on delivering the main happy path first. But before we do, I’m going to take a look at it and see whether there’s a simpler version of it that I could do first.
For example, let’s say we’re building a registration function, and one of the things we want to capture is the user’s date of birth. We could implement that as a date picker, with a nice calendar pop-up. But we could also do it as a simple text entry field, which is probably quicker and easier to build. Thus:
Register
becomes
Register – simple date field for DOB
Register – date picker for DOB
I sometimes call this “bronze plating” as opposed to “gold plating” – it’s good enough for an MVP, but we could make it better. As ever, whether and when we get round to making it better depends on how much we value the date picker compared to all the other things we still have to do on our backlog, as driven by the backlog prioritisation.
This is a great technique for resolving disputes within the team as to exactly how to deliver a given function. You break the flow down into the “bare minimum” (i.e. the MVP) and then have a separate story for each of the bells and whistles. Some of the bells and whistles might be deemed (by the Product Owner) as essential – that’s fine, we do them soon after the MVP story. Others will trickle down the backlog to be done later, or never. It’s funny how many times I’ve been told a given feature is “essential” only to discover it languishing at the bottom of the backlog six months later. Clearly, everything above it was more essential.
Here are a few other bronze-plating tricks you can use:
- Manual versus automatic. It’s all to easy to assume that because you’re building an IT system, everything has to be fully automated, whereas sometimes manual processing can be used for low volume tasks, or for a short period in an MVP. For example, a system I’m currently working on has no way to create new admin users other than a manual database script run by the webops team. It’s a pain but it doesn’t happen that often.
- Hard-coded versus configurable. Maybe a user has to select their title (Mr, Mrs etc.). Ideally the list of options would be populated from a configurable list which can be easily maintained by an admin user. But as a short-cut, the list could be hard-coded in the page.
- Assumed versus asked. Rather than asking the user to select an avatar for your blogging app, you could automatically assign them a random pattern in the first instance. Custom avatars come later.
- Simple versus complex architecture. Certain parts of your function might call upon complex architectural solutions. For example, an address lookup function requires integration with third party software, so is there a simpler option that avoids it initially, such as manual address entry? Be careful though – sometimes you want to address architectural risk early on, so you can “fail fast” if the concept isn’t going to work (see technique 999 below). There’s no right answer of course.
Technique 7: Split Into Steps
So, by now I have identified a single happy path flow for a single function, and I’ve pared it down to the bare minimum that makes sense as an MVP…
…but my development team still want it breaking down into smaller chunks for delivery, so that they can complete the stories quickly and see progress made.
One option here is to tell the developers that the story can’t reasonably be split down any further whilst still having any business value.
Another option is to split it down further, so that the valuable story is built up a bit at a time.
Importantly, we still want to slice the story vertically, so that each sub-story delivers something user-visible. We don’t want to slice the story horizontally – that would give us development tasks, not stories.
The obvious thing to do is to break the function down into individual steps. In the first instance, if the function involves the user traversing multiple screens, you can split into one story per screen. You can then split it down so that each screen is built up incrementally, even down to individual data fields. How small you go depends on your development team’s preferences. I often find they want the stories really small when the team is young, and they can cope with bigger stories as they mature.
A variant on individual steps is to build a “skeleton” for the function. You start out with a function that has a start and an end, but nothing in between. For example, a “Register” button which takes the user to an empty page with a “Submit” button. When the user clicks “Submit” they get a message telling them they have successfully registered. But actually nothing has happened. Then, story by story, you fill in the gaps – collecting the various bits of data and actually creating the registration. The point is that there are many different ways you could break it down, not necessarily in sequential order.
A further variant on the skeleton method is to build the front end user flow first but with no back end – all the back-end calls are stubbed out. This has the benefit that it allows you to see the full user flow early on, and adjust it if it isn’t working (although another way to do that is to build a simple HTML prototype).
By the way, another way to look at this technique is that you are splitting stories down from user goal level (sea level) to subfunction level (underwater level).
Technique 999: Split Out A Spike
A spike, is of course, a story that aims to deliver knowledge rather than production-strength working software. When faced with a story of uncertain size and/or architecture, teams will often “break out a spike” and spend some time doing either desk-based research or, more likely, actual coding in order to get a better understanding of size or approach.
On the surface this seems like a good idea, but I’ve experienced problems with spikes:
- Unclear objectives – spike stories are less likely to have clear acceptance criteria than business stories
- Unclear timescales – in theory, spikes should be timeboxed, but given an unknown task, it’s all to easy to just say “well, let’s see how it goes”
A combination of unclear scope and unbounded time is like Christmas come early for many developers I know – an opportunity to have a random play and see what happens. Even with a more disciplined developer, there’s a serious risk of getting carried away.
For example, let’s say our team is building APIs, and we have decided to use RAML to specify those APIs (RAML is an API markup language that’s quite fashionable at the moment). We want to publish the API documentation on our website and we decide a good approach would be to build a RAML-to-HTML conversion tool.
So, we break out a spike to build a RAML-to-HTML converter tool. One developer is assigned to the spike and off they go. Every day at the stand-up they report that it’s in progress, and should be done soon. Several weeks later it’s good to go, and good news – it’s fully compliant with RAML 1.0 and can generate HTML from any valid RAML file.
However, when we then get to looking at the APIs we actually want to build, we discover that we only need to use a subset of RAML 1.0. Half of what he built is wasted effort.
This example is based on a true story, but in truth it didn’t turn out so bad. Part way through the build, we changed our approach. Instead of continuing with the “RAML-to-HTML converter tool” spike story, we started defining business-facing stories to deliver actual documentation for actual APIs, and we focussed on building up the RAML-to-HTML converter a bit at a time, only building the bits we actually needed. With this approach, we avoided over-engineering the solution and we also delivered some actual business value sooner.
My mother always told me not to walk around with a sharp pencil in my mouth, on the grounds that if I were to trip and fall I might have a nasty accident and end up in hospital. To put it another way:
Be careful with spikes.
As a rule, I try to avoid spikes. Instead, I spend time with the developers to understand where the architectural uncertainty lies, and try to break up a story into sub-stories that allow them to explore the architecture a bit at a time, whilst still delivering business value along the way.
I’ve numbered this technique 999 for two reasons. Firstly, it’s a last resort, to be used after all the other techniques. Secondly, (in the UK) it’s the number you dial to call an ambulance, which seems apt for a technique that is potentially dangerous!
Story Splitting Is Hard
When I set out to write this article, I didn’t realise quite how long it was going to be. There’s a certain irony in the fact that I’ve written an article about splitting epics into stories that is in itself an epic.
The length of the article is telling – story splitting is complex and, in my experience, hard to do well. I’ve been doing it for quite a few years now and I’m still learning new tricks. It’s one of those skills that gets better with practice and experience, so don’t beat yourself up if you’re struggling!
In Conclusion
Given that several decades have probably passed since you started reading this article, it’s worth having a quick recap:
- Splitting stories is not just about making them small, it’s also about splitting out the low-value, high-effort bits so they can ripple down the product backlog.
- Splitting stories is iterative, and there’s no fixed number of iterations, so it makes little sense to define a fixed hierarchy “epic / feature / story / whatever”.
- How small you make your stories depends on what your team is comfortable with.
- Stories should split “just in time”, but only after doing enough analysis to understand the story well enough to do the split. Re-prioritise regularly to make sure the low value stories do indeed ripple down the backlog.
- Stories should be split vertically i.e. by decomposing user goals into sub-goals.
- Cockburn’s three named goal levels are useful to keep track of where you’re up to, especially “sea level” goals, which can be achieved by a single user at a single session and thus can be celebrated by a coffee break afterwards.
- There are a number of story-splitting techniques, and I’ve found there’s a consistent sequence that you can apply them in – as the story goes from larger to smaller.
- Story splitting is hard!
Putting It Into Practice
If you want to learn how to put what you’ve just read into practice, you might want to look at my Distance Learning Course.
Tony Heap is a freelance agile business analyst / agile coach / trainer based in the UK. He has worked for a variety of clients including HMRC, ASDA, Morrisons, NHS, RWE nPower, Arcadia, BT, Barclaycard and Egg. In his spare time, he likes to share his experiences and ideas on his blog www.its-all-design.com, and he is also an associate BA with Equal Experts, an award-winning agile consultancy specialising in simple software solutions for big business challenges. He is particularly interested in agile approaches and how they apply to business analysis. He is a requirements denier. Follow Tony on Twitter @tonyheapuk.
Copyright Tony Heap, Business Analyst Designer, its-all-design.com and Equal Experts
Comments
useful content on user stories