
 This article is based on content from the book, Executing Data Quality Projects: Ten Steps to Quality Data and Trusted Information™ (Morgan Kaufmann, 2008), by Danette McGilvray.
This article is based on content from the book, Executing Data Quality Projects: Ten Steps to Quality Data and Trusted Information™ (Morgan Kaufmann, 2008), by Danette McGilvray.
Data categories are groupings of data with common characteristics or features. They are useful for managing the data because certain data may be treated differently based on their classification. Understanding the relationship and dependency between the different categories can help direct data quality efforts.
For example, a project focused on improving master data quality may find that one of the root causes of quality problems actually comes from faulty reference data that were included in the master data record.
By being aware of the data categories, a project can save time by including key reference data as part of its initial data quality assessments. From a data governance and stewardship viewpoint, those responsible for creating or updating data may be very different from one data category to another.
THE SMITH CORP. EXAMPLE
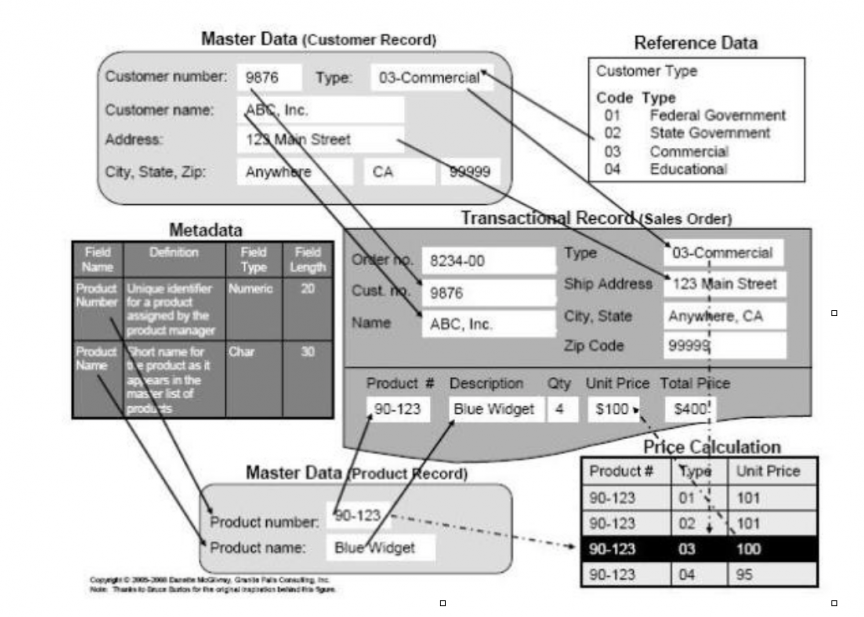
Your company, Smith Corp., sells widgets to state and federal government agencies, commercial accounts, and educational institutions. ABC Inc. wants to purchase four Blue Widgets from you. ABC Inc. is one of your commercial customers (identified as Customer Type 03) and has been issued a customer identifier number of 9876.
The Blue Widget has a product number of 90-123 and its unit price depends on customer type. ABC Inc. purchases four Blue Widgets at a unit price of $100 each (the price for a commercial customer) for a total price of $400.
Figure 1 below illustrates that transaction.
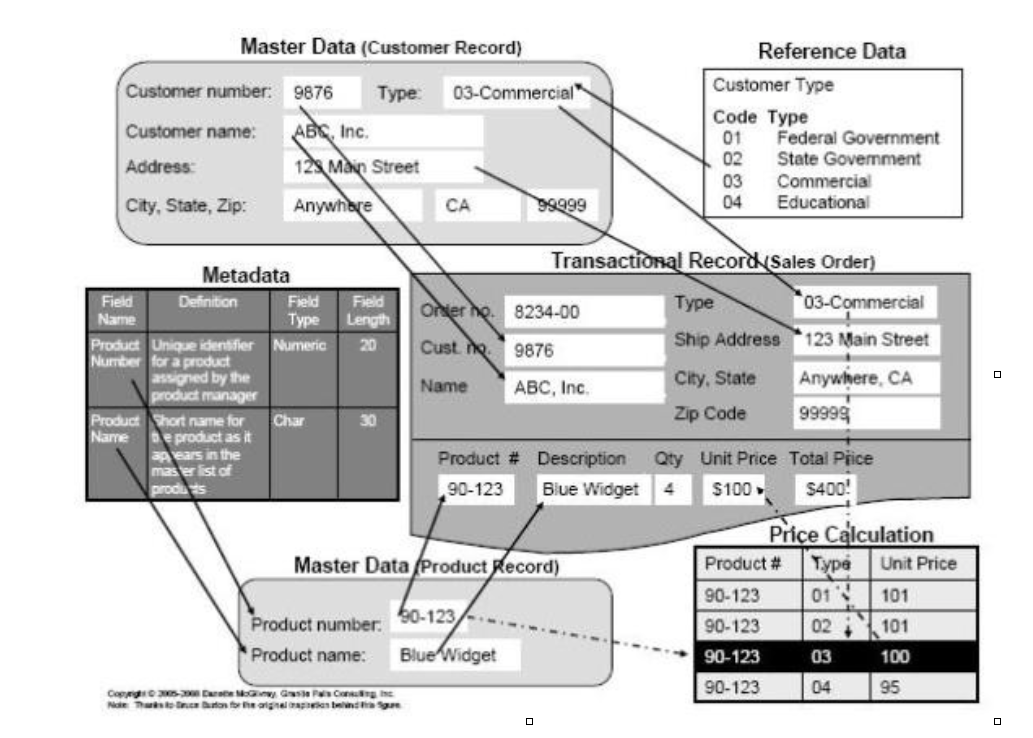
Figure 1 – An example of data categories.
When the agent from ABC Inc. calls Smith Corp. to place an order, the Smith Corp. customer representative enters ABC Inc.’s customer number in the sales order transaction. ABC Inc.’s company name, customer type, and address are pulled into the sales order screen from its customer master record. The master data mentioned are essential to the transaction.
When the product number is entered, the product description of “Blue Widget” is pulled into the sales order along with a unit price that has been derived based on the customer type. Therefore, the total price for four Blue Widgets is $400.
Let’s look at the data categories included in this example. We have already mentioned that the basic customer information for ABC Inc. is contained in the customer master record. Some of the data in the master record are pulled from controlled lists of reference data.
An example is customer type. Smith Corp. sells to four customer types, and the four types with associated codes are stored as a separate reference list. Other reference data associated with this customer’s master record (but not shown in the figure) are the list of valid U.S. state codes, which is used when creating the address for ABC Inc. An example of reference data needed for the transaction but not pulled in through the master data are the list of shipping options available (also not shown in the figure).
Reference data are sets of values or classification schemas that are referred to by systems, applications, data stores, processes, and reports, as well as by transactional and master records. Reference data may be unique to your company (such as customer type), but can also be used by many other companies.
Examples are standardized sets of codes such as currencies defined and maintained by ISO (International Standards Organization). In our example, the price calculations further emphasize the importance of high-quality reference data. If the code list is wrong, or the associated unit price is wrong, then the incorrect price will be used for that customer.
Why have the customer record and product record been classified as master data? Master data describe the people, places, and things that are involved in an organization’s business. Examples include customers, products, employees, suppliers, and locations. Gwen Thomas created a ditty sung to the tune of “Yankee Doodle” that highlights master data:
Master data’s all around
Embedded in transactions.
Master data are the nouns
Upon which we take action.
In our example, Smith Corp. has a finite list of customers and a finite list of products that are unique to and important to it — no other company will be likely to have the very same lists. While ABC Inc. is a customer of other companies, how its data are formatted and used by Smith Corp. is unique to Smith Corp.
For example, if Smith Corp. only sells to companies within the United States, it may not include address data (such as country) needed by other companies that sell outside of the United States and that also sell to ABC Inc. Addresses would be formatted differently within those companies to take international addresses into account. Likewise, Smith Corp.’s product list is unique to it, and the product master record may be structured differently from other companies’ product masters.
The sales order in the example is considered transactional data. Transactional data describe an internal or external event or transaction that takes place as an organization conducts its business. Examples include sales order, invoice, purchase order, shipping document, and passport application.
Transactional data are typically grouped into transactional records that include associated master and reference data. In the example, you can see that the sales order pulls data from two different master data records. It is also possible that reference data specific to the transaction are used — so not all reference data have to come through the master record.
Figure 1 also illustrates metadata, which means “data about data.” Metadata label, describe, or characterize other data and make it easier to retrieve, interpret, or use information. The figure shows documentation defining the fields in the product master record along with the field type and field length. Several kinds of metadata are described in Table 1.
Metadata are critical to avoiding misunderstandings that can create data quality problems. In Figure 1, you can see in the master record that the field containing “Blue Widget” is called “Product Name,” but the same data are labeled “Description” in the transactional record screen. In an ideal world, the data would be labeled the same wherever they are used. Unfortunately, inconsistencies such as the one in the figure are common and often lead to misuse and misunderstanding. Having clear documentation of metadata showing the fields (and their names) that are actually using the same data is important to managing those data and to understanding the impact if those fields are changed, or if the data are moved and used by other business functions and applications.
DATA CATEGORIES—WHY WE CARE
It is easy to see from the examples just given that the care given to your reference data strongly impacts the quality of your master and transactional data.
Reference data are key to interoperability. The more you manage and standardize them, the more you increase your ability to share data across and outside of your company. The significance of an error in reference data has a multiplying effect as the data continue to be passed on and used by other data.
The quality of master data impacts transactional data, and the quality of metadata impacts all categories. For example, documenting definitions (metadata) improves quality because it transforms undocumented assumptions into documented and agreed-on meanings so the data can be used consistently and correctly.
As mentioned previously, your company’s data are unique (master product, vendor, customer data, etc., reference data, metadata). No other organization will be likely to have the very same data list. If correct and managed conscientiously, your data provide a competitive advantage because they are tuned for your company needs.
Imagine the cost savings and revenue potential for the company that has accurate data, can find information when needed, and trusts the information found. Quality must be managed for all data categories in order to gain that competitive advantage. Of course, you will have to prioritize your efforts, but consider all the data categories when selecting your data quality activities.
Learn More – Ten Steps to Data Quality
To learn a proven method for creating, improving, and managing information and data quality, join Danette in London on 4-5 December 2014, for the course Ten Steps to Data Quality. This course is based on her extensive experience and book Executing Data Quality Projects: Ten Steps to Quality Data and Trusted Information™ (Morgan Kaufmann, 2008).
About the Author
 Danette McGilvray is President and Principal of Granite Falls Consulting, Inc., a firm that helps organizations increase their success by addressing the information quality and data governance aspect of their business efforts. She is the author of Executing Data Quality Projects: Ten Steps to Quality Data and Trusted Information™. An internationally respected expert, Danette’s Ten Steps™ approach has been embraced as a proven method for managing information and data quality in the enterprise. A Chinese-language edition is also available and her book is used as a textbook in university graduate programs. She received IAIDQ’s distinguished Member Award in recognition of her outstanding contributions to the field of information and data quality. She can be reached at danette@gfalls.com.
Danette McGilvray is President and Principal of Granite Falls Consulting, Inc., a firm that helps organizations increase their success by addressing the information quality and data governance aspect of their business efforts. She is the author of Executing Data Quality Projects: Ten Steps to Quality Data and Trusted Information™. An internationally respected expert, Danette’s Ten Steps™ approach has been embraced as a proven method for managing information and data quality in the enterprise. A Chinese-language edition is also available and her book is used as a textbook in university graduate programs. She received IAIDQ’s distinguished Member Award in recognition of her outstanding contributions to the field of information and data quality. She can be reached at danette@gfalls.com.