
So, you want to predict the future, make the right calls and die happy? Well, you’ll need to build a robot overlord to help you. You can get a sense of the likely trajectory of your life and business using some whiz-bang computer tech (predictive analytics). And, more importantly, you can manipulate reality (using prescriptive analytics) so you end up living your preferred future (the one that sees you wealthy, happy and surrounded by your loving family) instead of your feared one (the one that sees you bankrupt, sad and alone).

Justin Lyon, Founder and CEO, Simudyne®, Barclays Techstars ’17

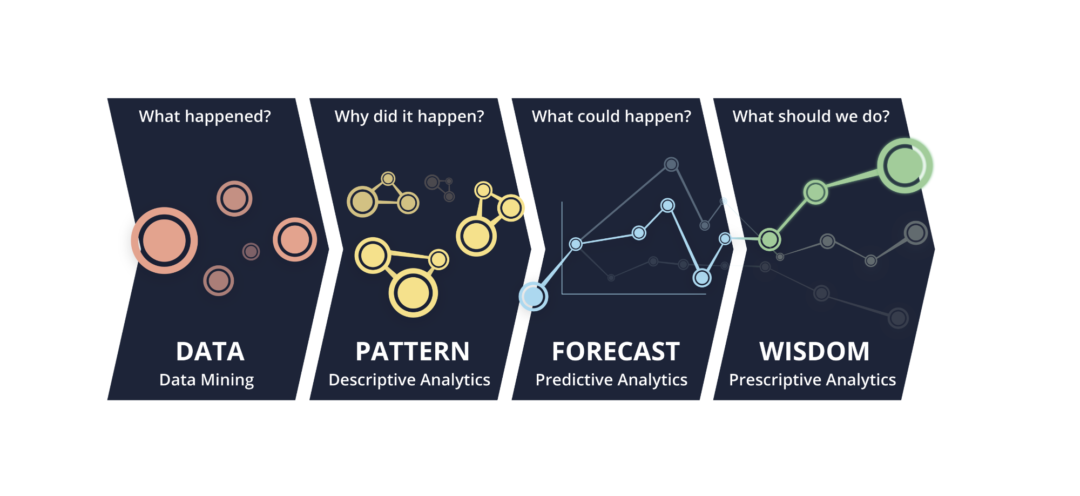
Let’s start with some vocabulary.
- Descriptive Analytics is about trying to understand what happened.
- Predictive Analytics is about understanding what could happen.
- And Prescriptive Analytics? Well, that’s all about figuring out what we should do to make our preferred future happen, rather than our feared one!
Now, let’s dive into the details…
Descriptive Analytics
For thousands of years, we have turned data into insight. What happened? Where did it happen? What are the implications?
At the British Museum one can see a Sumerian clay tablet that is over 6000 years old containing payroll data. Imagine that! We’ve been doing this for 6000 years! Fast-forward to today, we still capture such data, interestingly also on tablets, but of silicon rather than clay.
Beyond the what and where that data shows us, we can also start to ask ‘Why did something happen?’ We can make inferences from the data and turn it into knowledge about why something happened. It’s the beauty of 20/20 hindsight.

But, be careful. Often, the why is not really present in the descriptive analytical models that we use to interpret the data. Even with 20/20 hindsight, you must use statistical principles and good science to justify the inferential leap from data to knowledge. It’s really, really easy to mess this up. It’s very easy to turn data into something that you think is knowledge, but is not. Worse yet, you might not even know that this has happened. You have been warned!
Predictive Analytics
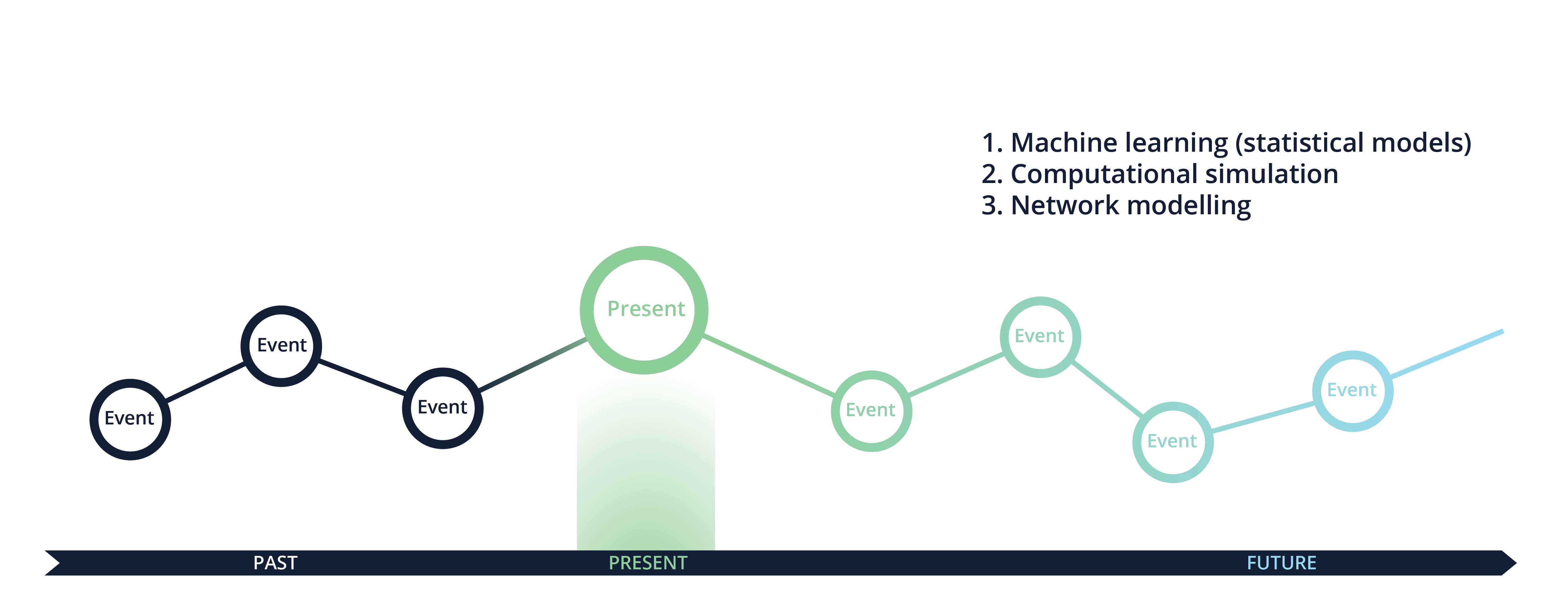
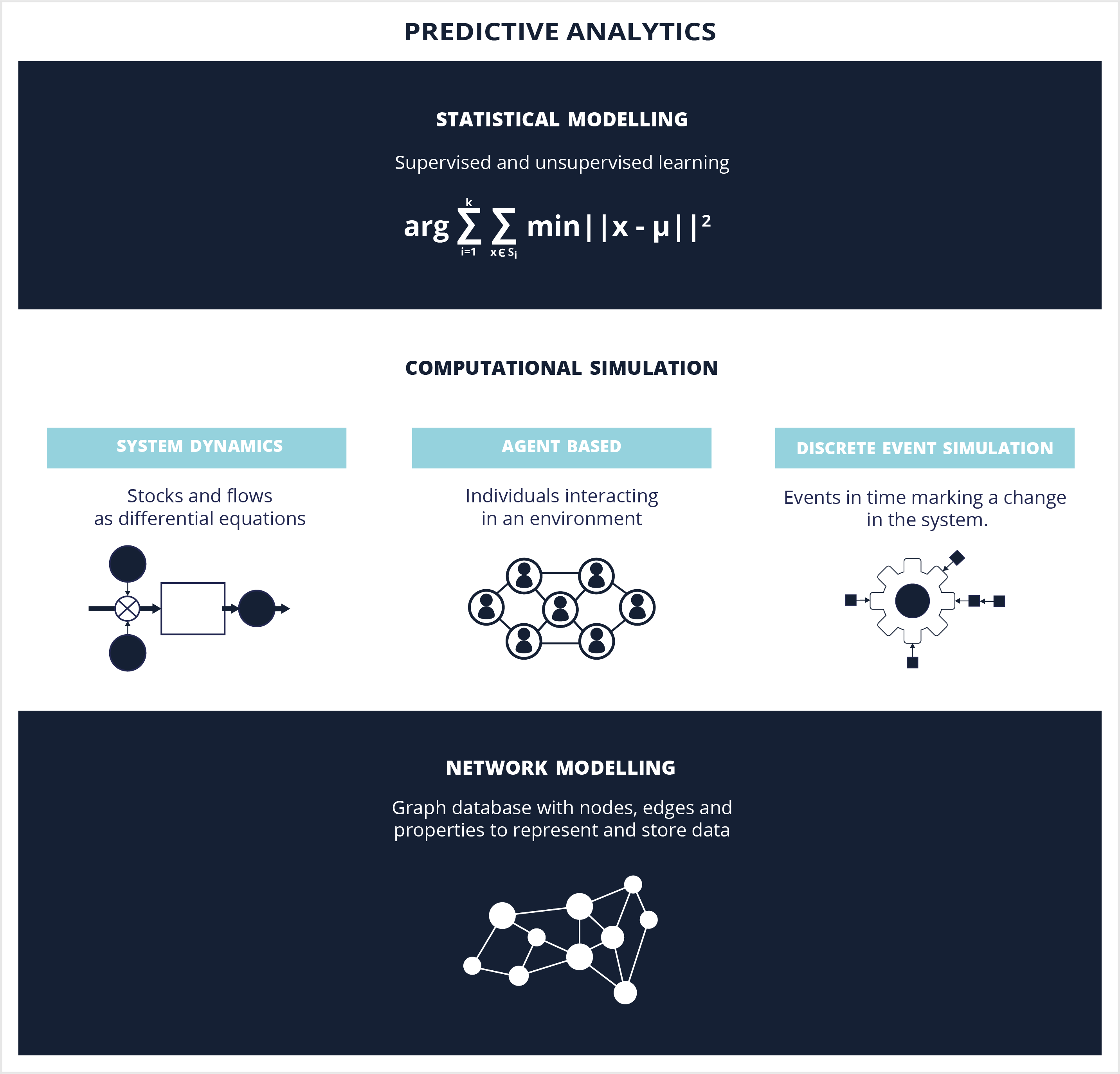
So, we build models to understand the past and how we got to today, but we also build models to predict the future. Here are three ways to predict the future:
1. Machine Learning
Most people are very familiar, at least conceptually, with the first. And, to be clear, there is no need to make a sharp distinction between “statistics” and “machine learning.” Statistical models make it possible to identify relationships between variables and to understand how variables, working on their own and together, influence an overall system. They also allow us to make predictions and assess their uncertainty.
Machine learning/statistical models are usually presented as a family of equations that describe how some or all aspects of the data might have been generated. Typically these equations describe probability distributions, which can often be separated into two components that can be specified in terms of some unknown model parameters that need to be estimated from the data (NB: systematic component and a noise component).
Missing data is always an issue. Some statistical approaches have built-in methods for dealing with missing values. Other approaches don’t, but still require that you provide complete data. Since you’re unlikely to have complete and clean data in the real-world, you have to impute the data before you model. There are many different approaches to data imputation. Some are simple, like using the mean for a variable, and others are more sophisticated, like predicting the missing entries for a variable using that variable as a response, and all the values as input variables.
But be careful. You can make lots of predictions using statistical modelling, but if you forget about error bars, about heterogeneity, about noisy data, about the sampling pattern, about all the kinds of things that you have to be serious about if you’re an engineer and a statistician, then you might be lucky fool and occasionally solve some real interesting problems. But you will occasionally make some disastrously bad decisions. And you won’t know the difference before hand. You will just produce these predictions and hope for the best.
Statistical approaches take our past data and provide forecasts based on past data only. They are useful when the number of variables are large and disorganised. This means that the precision of the forecast improves with increasing numbers of variables, as long as the variables are disorganised. But, what if the variables are not random? Then, statistical modelling is not the right tool to pull out of the prediction toolbox!
Why not??
So, we can see how over the past several hundreds years, by using descriptive analytics, we have solved many difficult problems made up of few variables leading to dramatic improvements to our lives and our productivity. Let’s call this simple complexity. More recently, people have also solved problems made up of many disorganised variables, where the precision of forecasts of the whole system increases with the number of variables as demonstrated empirically over many years by statistics. Let’s call this disorganised complexity.
The first, solving problems with few variables, led to an understanding of Newton’s laws of motion and technologies like the telephone and airplane.
The second, that is, solving problems with many disorganised variables, led to an understanding of: the motion of atoms and the foundations of thermodynamics; the motion of the stars; the evolution of our species; and even how to insure people profitably or sell them things they want, but do not need. All have been derived from statistical considerations.
And, that brings us to the end of the 20th century – around the time when we created computers – which, for the first time in our species history, gave us an ability to address the multitude of problems that exist between these two immensely separated poles. A vast number of ‘critically-important-to-our species-survival’ problems lurk in this vast expanse. These are messy problems, wicked problems. These are problems that involve dealing simultaneously with a sizeable number of variables which are interrelated into an organic whole. This is organised complexity. Many of today’s problems are just too complicated to yield to the nineteenth century techniques which were so dramatically successful on two-, three- or four-variable problems of simplicity. Nor can they be handled with the statistical techniques so effective in describing average behaviour in problems of disorganised complexity.

On what does the price of a house depend? How can housing prices in a city be wisely and effectively stabilised? To what extent is it safe to depend on the free interplay of such economic forces as supply and demand? To what extent must systems of economic control be employed to prevent the wide swings from boom to bust, from prosperity to depression?
We live in a complex world. We adapt to the changes we encounter in our complex environment. The technical term is that we live in a complex adaptive system. These are systems made up of many variables, but these variables are organised, rather than disorganised. By definition, this means that statistical approaches are doomed to failure.
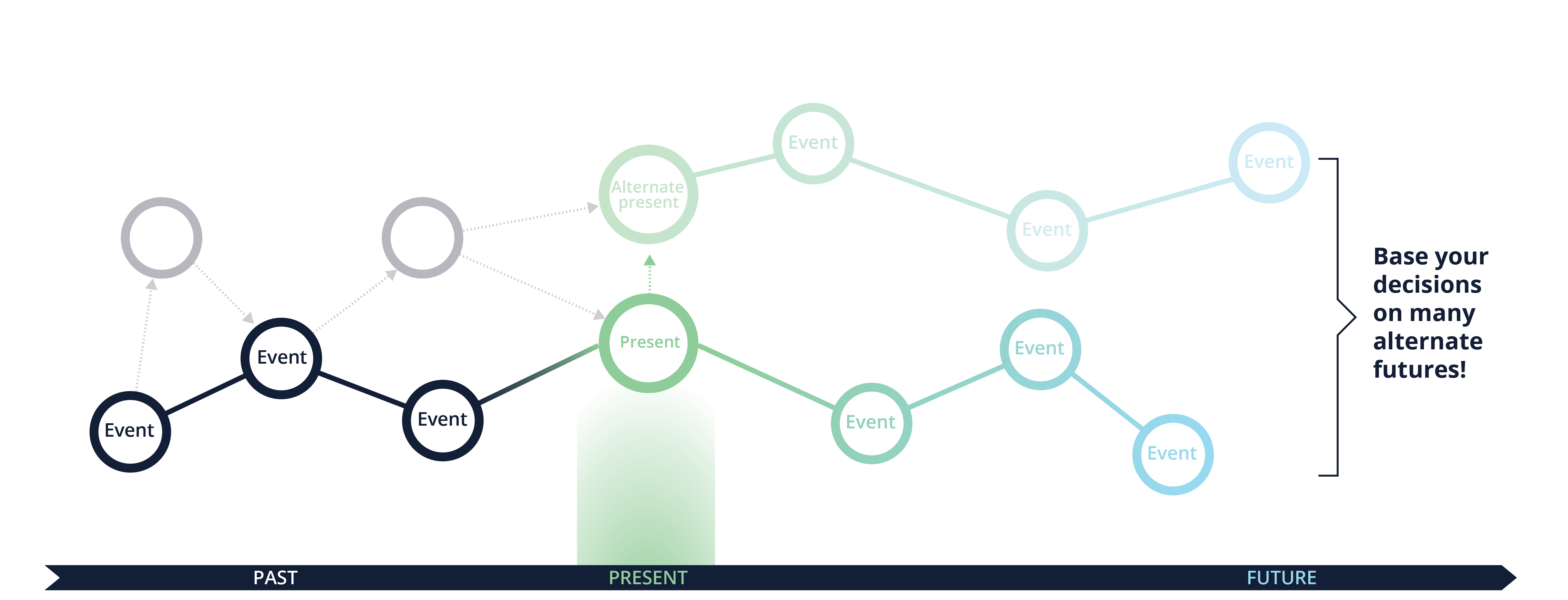
A tiny change to circumstances to an event in the past could have triggered a whole different outcome. In fact, there exist many alternative presents that did not happen but might have happened with a given probability.

The Queen famously asked academic economists at the London School of Economics about the 2008 crisis, “Why did nobody notice it?” Their response was that they “lost sight of the bigger picture” and that no one could have seen the crisis coming.
They were wrong. You could absolutely predict it. And several people did. They did it by using computers and techniques that enable us to understand organised complexity. They did it with computational simulation.
2. Computational Simulation
So, we’ve discussed statistical modelling. Let’s move on to computational simulation and it’s role in prediction when dealing with complex adaptive systems.
We can define the economy or other complex systems in terms of coupled ordinary differential equations, i.e., by using system dynamics modelling techniques. The models are created using a drawing canvas (to make the mathematics a bit easier) and a double entry bookkeeping system (to align with accounting standards). In practice, you need to convert the models into Java and deploy it to cloud infrastructure to handle the massive amounts of data generated and the computationally expensive calculations. System dynamics was used effectively by Dr. Keen to predict the 2008 crisis. He was one of 12 people who won an award for his prediction. System dynamics is incredibly easy to learn, but is frightfully difficult to master.
Yet, whilst incredibly powerful for forecasting and improving decision making, system dynamics is not enough.
Way back in 2006, scientists identified opportunities to use another advanced modelling technique to understand economies. It’s called agent based modelling. As reported in the New Scientist in July 2015, agent based models use “modern computers’ number-crunching power to simulate people and institutions who do not necessarily behave optimally, and who interact.” For example, this approach can be used to model economic situations involving financial networks, such as that faced by Cypriot banks with unpaid Greek debts in 2013.
Most importantly, by using these models, policymakers learn that no one strategy ever works for very long because, as I already mentioned, reality is messy and exhibits organised complexity. This insight is painful, because it destroys the concept that what worked yesterday, will work today. It might, but it might not. The only option we have is to relentlessly study the situation using system dynamics and agent based modelling and test the decisions in a simulation, where we don’t waste taxpayer money or kill people.
Yet, even combining system dynamics and agent based modelling is not enough. Let’s introduce the third technique that’s useful for predictive analytics.
3. Network Modelling
The inability to capture, robustly, the interconnections between elements in traditional models has caused numerous failures for corporations and entire economies. For example, before the financial crisis, regulators only looked at financial institutions in isolation and not how they are connected with each other. This was a terrible, if not criminal, mistake. During the credit crisis, the Fed had no tools to assess the impact on other firms of letting Lehman default, nor the benefit of proposed rescue packages to other institutions. For value chains, the failure of one critical company can lead to the bankruptcy of many other companies in a way that defies common sense.
Whilst system dynamics and agent based modelling both specifically address interconnections, there is another powerful tool from complexity science for understanding interconnections even more robustly.
It’s goes by several names: network analysis or network modelling and graph analysis or graph database.
In 2009, Andy Haldane at the Bank of England, said that “in time, network diagnostics such as these may displace atomised metrics such as VaR in the armoury of financial policymakers”
That time is now.
For example, we can now map the hundreds of thousands of financial institutions interacting in the global financial system to identify systemically important organisations. We can quickly and in near real-time identify emerging liquidity and operational risks. And, as each node in the network are represented both as stocks and as agents (where appropriate), we can assign any number of attributes and variables to each node and then run simulations to look for emergent behaviour resulting from the interactions of these agents in a complex, global system full of positive and negative feedback loops.
In addition to answering enormously complex financial stability questions, we can also look at how various shocks might impact the financial markets. For example, we can simulate cyber attacks to identify which institutions are the most vulnerable to triggering a cascading failure so as to highlight which vulnerabilities must be fixed to enhance resiliency. We can now monitor liquidity and credit risk in interbank networks. We can now identify escalating risks and contagion in global financial markets. The approach is proven. It’s recently been used to detect early warning signals for the 2015 Chinese stock market bubble and last year’s energy sector meltdown.
Summary
Business executives, by definition, are focused on execution. Clear, timely and effective execution is imperative in a world experiencing unprecedented technological change. The what-could-should model can help leaders organise their thoughts around business analytics and understand which technologies they require to achieve their objectives.
WHAT
The ability to understand and analyse events in the past has been possible with a variety of techniques from “Descriptive Analytics”. This field tells us what happened.
COULD
The field of “Predictive Analytics” takes this a step further and allows us to make predictions about what could happen in the future. Predictive analytics is comprised of three techniques. Machine learning makes it possible to identify relationships between variables and to understand how variables, working on their own and together, influence an overall system. They also allow us to make predictions and assess their uncertainty. Computational simulation is incredibly useful for predictions involving complex adaptive systems. It involves techniques including system dynamics, agent based modelling and others. Network modelling is a powerful tool from complexity science for understanding interconnections.
SHOULD
Combining these two fields of study can lead us to suggest what should happen. This field is known as “Prescriptive Analytics” and it seeks suggest the best outcome given a number of choices. Let’s dive into the details.
Prescriptive Analytics
By using statistical modelling, computational simulation and network modelling, you can explore millions of different plausible futures. By doing so, you can identify strategies and tactics that work under the widest range of plausible (or even implausible) futures. In other words, you can design resilient strategies. They will not necessarily be optimal at all times. You may make significantly less money at some points in time pursuing a resilient strategy than you would pursuing ‘all-or-nothing’ strategies. But, you’re far more likely to survive if you’re resilient to whatever uncaring nature or your fellow humans throw at you.
The challenge, however, is that people suck at making decisions and many senior policymakers and executives hate deeply mathematical conversations. So you have to build beautiful user interfaces on top of these predictive models so that you can draw the people into using them to experiment safely. Basically, you’ve got to build user interfaces on top of your predictive models that look and feel like a multi-player video game.
The more you and your teams play a video game the more likely you are win. Similarly with simulations, the more times the human plays it the more knowledgeable they’re going to be about a situation. What we found is in the past, if the simulation was boring or it was too mathematically heavy, then humans would only play it one, two or three times. They didn’t get the rich learning that we wanted them to get.
Drawing them in is key because so many of the strategies and tactics thrown up by highly complex mathematical systems are counter-intuitive. Now, many executives say, ‘Well, no. The math must be wrong, the model must be wrong. My mental model is accurate.’ That’s because their mental model is based on flawed thinking, because they’re limited by human cognitive biases… Humans over millions of years have evolved incredible skills, but we are unable solve non-linear equations in our head. No one can. I don’t care how clever you think you are. You can’t do it. It’s only in collaboration with our computers that we can transcend our evolutionary limitations.
You can run tens of thousands of simulations and identify resilient and optimal strategy. Yet, it might take six months or a year for people to wrap their head around it and implement the change management processes to actually execute. That’s unfortunate… at some point you won’t have the time to allow people to beat their head around what the right decision is. The computer will simulate, make a decision and then execute – all without human involvement.
After running through what, could and should, the next obvious question is why?! The concepts underlying prescriptive analytics have been around for hundreds of years; however, several technological advancements have recently come together to unlock its potential:
- improvements in computing power
- the development of sophisticated algorithms
- the linking of artificial intelligence with computational simulation
- the availability of large data sets
This is already happening. Since the 1990’s, routine work, whether manual or cognitive, has stagnated because we’ve been relying on computers to do more and more of that type of work.
And now it’s accelerating. If your company was a representative sample of all UK jobs, then half of your co-workers, yes half, will be out of your job right quick, replaced by an AI.
We call it Providence.
With the right platform that leverages these technological breakthroughs, business leaders will be able to understand, prepare for and manipulate the future. This is a fundamental change in how business will be done.
The world of routine work, like the kind that once filled our office buildings and our factories, is dwindling, leaving only two kinds of jobs: lousy jobs that require so little thought that they pay next to nothing , and lovely jobs that require so much thought that the salaries are exorbitant.
Make no mistake about it. Many of us who are building these technologies believe that the goal of the future should be full unemployment.
And for those of you who are stressed about all of this, please, get on your Kindle right now and read this book. Today. Seriously. It should change your life.

Justin is one of the world’s foremost experts in the field of computer-based simulation and a regular speaker on the application of AI, advanced analytics and simulation technology in solving complex problems and enabling better decisions for the world’s business, government and civic leaders. In a market densely populated with companies deriving insight from data for their customers, Justin’s entrepreneurship, vision and technical expertise has helped to craft technology that revolutionizes decision-making for the 21st century – turning insight into foresight. Justin studied at MIT and has worked in software development, strategic consultancy, sales and marketing for over 20 years. He is the founder of the pioneering technology company, Simudyne and a Director of ORDACH, a cyber-security SaaS solution developed as part of the Cyber London Accelerator (CyLon).
Copyright Justin Lyon, Simudyne