

In 1988, a cell phone weighed approximately 2 pounds, cost nearly $4,000, offered 30 minutes of talk time—and no other function—having taken some 10 hours to charge. The Motorola DynaTAC 8000X was broadly known as “the brick” and was wildly popular eye-candy among the jet set of the time.

Dr. Barry Devlin, Founder and Principal, 9sight Consulting
Barry will be presenting the following courses via live streaming, ‘Essentials of Data Warehouses, Lakes and BI in Digital Business‘ 22-23 March 2021 and ‘From Analytics to AI: Transforming Decision Making in Digital Business‘ 24 March 2021
View the next entries in this series: Part 1, Part 2, Part 3
The same year, your office desktop might have been adorned with an Apple Macintosh II or an IBM PS/2 with 512K of memory, a 20MB hard drive—if you were lucky—and a choice of a monochrome or color monitor with an eye-catching resolution of 640×480 pixels.
Of more interest to a reader of IRM UK Connects would have been the Teradata DBC/1012, a massively parallel processing database system with a maximum of a thousand processors and 5 terabytes of disk storage at the very top of the range. Few customers reached those dizzying numbers: the costs were eye-watering. Although Teradata is now almost synonymous with data warehousing, its marketing material spoke only of a “Data Base Computer System”, because the phrase data warehouse was just about to be unleashed.
Enter the data warehouse
Over thirty years ago, in February 1988, the IBM Systems Journal published the first description of a data warehouse architecture, written by myself and Paul Murphy. Entitled “An architecture for a business and[1] information system” (Devlin and Murphy, 1988), the article summarized architectural work carried out in IBM leading to “the EMEA [Europe, Middle East, and Africa] Business Information System (EBIS) architecture as the strategic direction for informational systems [that proposed] an integrated warehouse of company data based firmly in the relational database environment.”
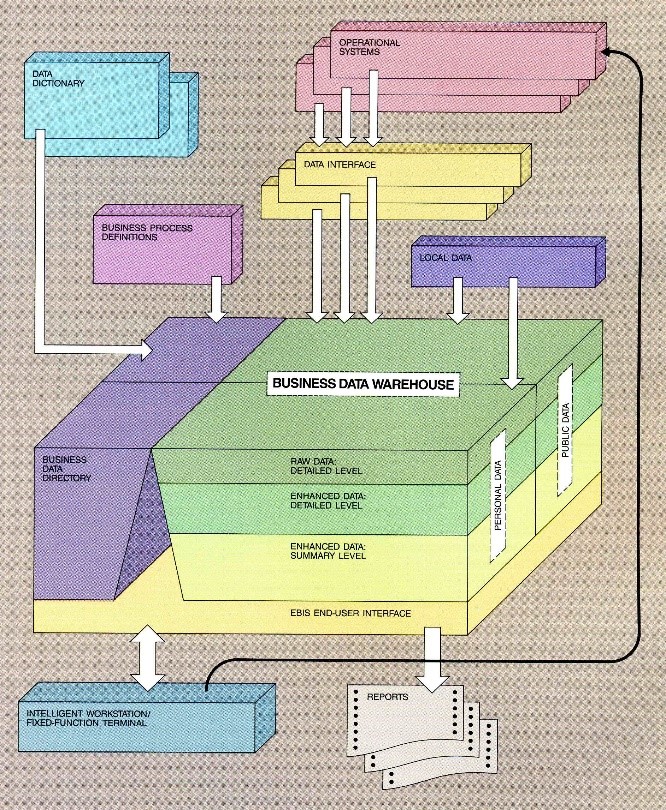
The key architectural figure of the article, reproduced here in Figure 1, would be instantly recognizable by any data warehouse practitioner today. Front and center is the business data warehouse, a single logical repository containing public and personal data at raw, detailed, and summary levels from operational and local (personal) systems. This data is described in a business data directory sourced from a data dictionary and business process definitions. Data is made available to business users via workstations and reports. Key components of the architecture, including the update strategy and user access, are described in some detail elsewhere in the paper. The structure of the data in the business data warehouse is also illustrated as a conceptual set of tables—such as customers, employees, products, orders, and so on—matching the user’s perception of the subset of business information to which he or she needs access.
Embedded in this architecture, but seldom discussed, is the postulate that operational and informational systems are separated for business and technical reasons. I will return to this assumption later in this article, when discussing the future of the data warehouse.
IBM rolled the concepts of this architecture into the IBM Information Warehouse Framework in 1991. Focused on a proprietary approach and, trademarking the term Information Warehouse, IBM missed the opportunity to define and monetize the market for decision-making support systems based on relational databases. In retrospect, that trademark is unfortunate. Information is surely more representative of what a warehouse should deliver, but we are left with data warehouse for general use, and it was this term that Bill Inmon popularized in the early 1990s (Inmon, 1992).
But, what is a data warehouse?
It was Inmon who introduced the oft-quoted definition of a data warehouse: a subject-oriented, nonvolatile, integrated, time-variant collection of data in support of management decisions. The four data characteristics of this simple and memorable definition are implicit in the EBIS architecture and are emergent in Inmon’s 1992 book. As the basis for much thinking about what a data warehouse looks like, these terms bear closer consideration.
- Subject-oriented: On one hand, this corresponds to the idea introduced in the EBIS architecture and echoed by Inmon that the data should be represented in terms and structures, such as customer, product, order, transaction, etc., that are familiar to business people. On the other hand, a more formal interpretation aligns the term and structure to the enterprise data model described by John Zachman (Sowa and Zachman, 1992). These two views map to the perceived primary purpose of the data warehouse: The subject-oriented view is framed to directly support decision makers, while an enterprise data model is aimed more at integrating data from diverse sources.
- Integrated: This characteristic springs from the understanding that data extracted from diverse operational sources may be incoherent for reasons of meaning (for example, different definitions of profit) or timing (because of time zones or other reasons). Integration means reconciling these differences in various ways to deliver a “single version of the truth (SVOT)” that can be used across the enterprise. SVOT has long been recognized as an ideal that is unachievable in practice. However, integration of key data to common standards remains an important goal for data warehousing that has been under-emphasized in the data lake approach.
- Nonvolatile: In simple terms, this reflects a long-standing business need to be able to recreate a business situation as of a particular date and time in the past, either for reporting or as a basis for what-if simulations. Therefore, unlike many operational systems and modern external data sources, a data warehouse must maintain an ongoing and stable record of both current and historical data states. Ideally, data is never deleted.
- Time-variant: All data records in the warehouse are timestamped. This is a consequence of the previous characteristic. However, the exact nature of the timestamp has long been debated. The simplest approach is to record the time of loading into the warehouse. In general, this is insufficient for most business purposes. Therefore, bitemporal and, more recently tri-temporal, schemata—where each record carries multiple timestamps—have been implemented or promoted in the past decade to provide more and better ways of analyzing and using data over time (Johnston, 2014).
As experienced data warehouse practitioners are aware, these characteristics are neither complete nor fully congruent. At a high level they provide welcome guidance for design. Nonetheless, every data warehouse implementation ends up balancing them against one another and trading them off against business needs and the limitations of chosen or required technology. One example of such a trade-off involves simplifying integration by focusing on a subject-oriented data warehouse for a single department, perhaps better called a data mart. Another example is the dimensional data warehouse, discussed in the following section, where trading business demands for early delivery are accommodated by redefining the concept of subject orientation.
This situation continues to this day. Despite claims to the contrary, data lakes do not eliminate the need for these compromises, and in some cases, promote practices contrary to the above characteristics and introduce new challenges, as discussed in the section “Diving into the data lake”.
Competing data warehouse structures
What is missing from the EBIS architecture and, indeed, in Inmon’s early book is the hub-and-spoke structure of a centralized enterprise data warehouse (EDW) that provides the reconciliation point for data from diverse sources feeding multiple departmental data marts. This structure, often referred to as the Inmon data warehouse, arose first from technological necessity: General purpose relational databases in the 1990s weren’t powerful enough to handle multiple concurrent user queries with varying data needs against a single, enterprise-level, subject-oriented database. One solution—and the solution that sticks most closely to the intent and principles of the EBIS architecture—was to split the data warehouse into two, or sometimes more, layers. Data is integrated/reconciled in the EDW and then distributed to businesspeople in more query-friendly, departmentally focused data marts, as shown in Figure 2.
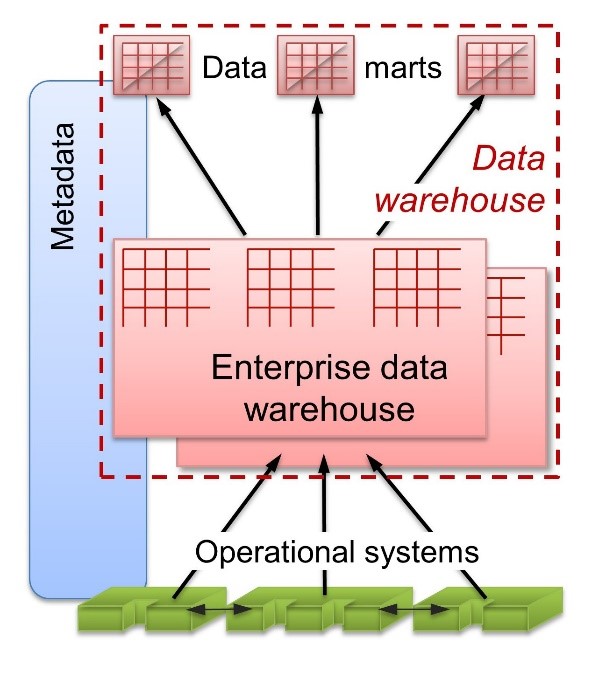
This approach comes with two major challenges. First, its layering implies that at least some part of the EDW—often found to be quite a large part—must be built before any data marts can be delivered. Business needs come later, conceptually at least, and careful project management is a prerequisite to balancing business demand with the challenging reality of data diversity. Second, data must be moved sequentially from layer to layer, so each additional layer delays the arrival of data to where it’s needed. With timeliness of decisions increasingly important, such delays are unwelcome.
Ralph Kimball took a different approach to solving these build and runtime delays. He adopted a different data model and database structure that was optimized for the most common type of analysis: slice-and-dice and drill-down. This approach is the dimensional or star-schema data warehouse (Kimball, 1998). Kimball starts from the immediate analysis needs of departmental business processes to create a performant database consisting only of relevant facts and dimensions. Departmental level star schemas are subsequently related via conformed dimensions.
By the turn of the century, the debate between these two approaches had allegedly turned into a war (Breslin, 2004); whether concocted by the press or for the benefit of one or other of the parties remains unclear. The reality is that each approach has its strengths and weaknesses. In some cases, a hybrid approach can be taken, where the data marts are dimensional and fed from a reconciliation layer in the EDW.
Next up: In Part 2 of this series, we’ll dive into the data lake.
Dr. Barry Devlin is among the foremost authorities on business insight and one of the founders of data warehousing, having published the first architectural paper in 1988. With over 30 years of IT experience, including 20 years with IBM as a Distinguished Engineer, he is a widely respected analyst, consultant, lecturer and author of the seminal book, “Data Warehouse—from Architecture to Implementation” and numerous White Papers. His 2013 book, “Business unIntelligence—Insight and Innovation beyond Analytics and Big Data” is available in both hardcopy and e-book formats. As founder and principal of 9sight Consulting (www.9sight.com), Barry provides strategic consulting and thought-leadership to buyers and vendors of BI solutions. He is continuously developing new architectural models for all aspects of decision-making and action-taking support. Now returned to Europe, Barry’s knowledge and expertise are in demand both locally and internationally.
Copyright Dr. Barry Devlin, Founder and Principal, 9sight Consulting
Breslin, M., “Data Warehousing Battle of the Giants: Comparing the Basics of the Kimball and Inmon Models”, Business Intelligence Journal, Winter 2004
Devlin, B., “Data Warehouse: from Architecture to Implementation”, Addison Wesley, Reading, MA, 1997
Devlin, B.A. and Murphy, P.T., “An architecture for a business and information System”, IBM Systems Journal, Vol 27(1), 1988, http://bit.ly/EBIS88
Inmon, W.H., “Building the Data Warehouse”, QED Information Sciences, Wellesley, MA, 1992
Johnston, T., “Bitemporal Data: Theory and Practice”, Morgan Kaufmann, Waltham, MA, 2014
Kimball, R., “The Data Warehouse Toolkit”, Wiley and Sons, Hoboken, NJ, 1996
Sowa J.F. and Zachman, J.A., “Extending and formalizing the framework for information systems architecture”, IBM Systems Journal, Vol 31(3), 1992