

Data warehouse—into the future
The death of the data warehouse has been proclaimed many times and with increasing frequency in this current decade as the data lake has become ever more popular. To paraphrase Mark Twain’s alleged riposte: “reports of its death have been greatly exaggerated.”

Dr. Barry Devlin, Founder and Principal, 9sight Consulting
Barry will be presenting the course ‘Design and Build a Data Driven Digital Business—From BI to AI and Beyond‘ via live streaming 1-3 June 2020.
He will also be presenting the course ‘Essentials of Data Warehouses, Lakes and BI in Digital Business‘ face-to-face and via live streaming 16-17 November 2020, London
View the previous entries in this blog series: Part 1, Part 2, Part 3
Although the story of the data warehouse over the past thirty years has been marked by failures as well as successes, its current standing is a testament to the strength of the original architectural thinking and the support and extension of the architecture by many practitioners over the decades.
When dealing with traditional process mediated data, the data warehouse architecture as updated in Devlin, 1997 continues to satisfy the majority of business intelligence (BI) needs. However, it is equally clear that the data warehouse cannot address all the informational needs of the modern digital business, particularly as they pertain to Internet-related data. A comprehensive extension of the original data warehouse is provided in “Business unIntelligence” (Devlin, 2013). Although the term data lake failed to make an appearance there, Internet-related data was dealt with extensively under the topics of machine-generated data and human-sourced information. The resulting architecture was detailed at conceptual (IDEAL) and logical (REAL) levels, and also described in a previous Business Intelligence Journal article (Devlin, 2015).
The IDEAL and REAL architecture offers a longer-term vision of information preparation and use in the enterprise and in the world at large. In the shorter term, a simple picture that positions the data warehouse and the data lough can clarify much of the current confusion in the industry about both concepts, as shown in Figures 1 and 2.

As previously observed, today’s IT landscape is first characterized by a division between operational (run the business) and informational (manage the business) concerns. The traditional data warehouse architecture, shown in simplified form on the left of Figure 1, strongly supports this long-standing view, with a separate layer of operational systems feeding process mediated data into the warehouse. The decisions and actions output from the data warehouse are traditionally labelled BI.
On the right, the data lough receives raw Internet-related data—both machine-generated and human-sourced—as the basis for analytics. Although commonly perceived as an informational environment, deeper examination shows that a significant backflow of data and models into the operational environment is required to deliver real-time operational analytics. In addition, as depicted by the gray, dashed arrows, substantial bidirectional data sharing is required between the data lough and the operational systems and between the data lough and the warehouse to facilitate analytics and BI.
These data flows and interactions between the data lough and the operational world, in addition to long-standing timeliness challenges encountered in operational BI, suggest that the original separation of operational and informational activities should be reconsidered. The possibility of reuniting the data warehouse with operational systems was discussed in Devlin, 2013. Indeed, the direction can be seen in practice in SAP HANA. The growth of operational analytics driven from the data lough further extends the need to explore if and how such reunification could be achieved.
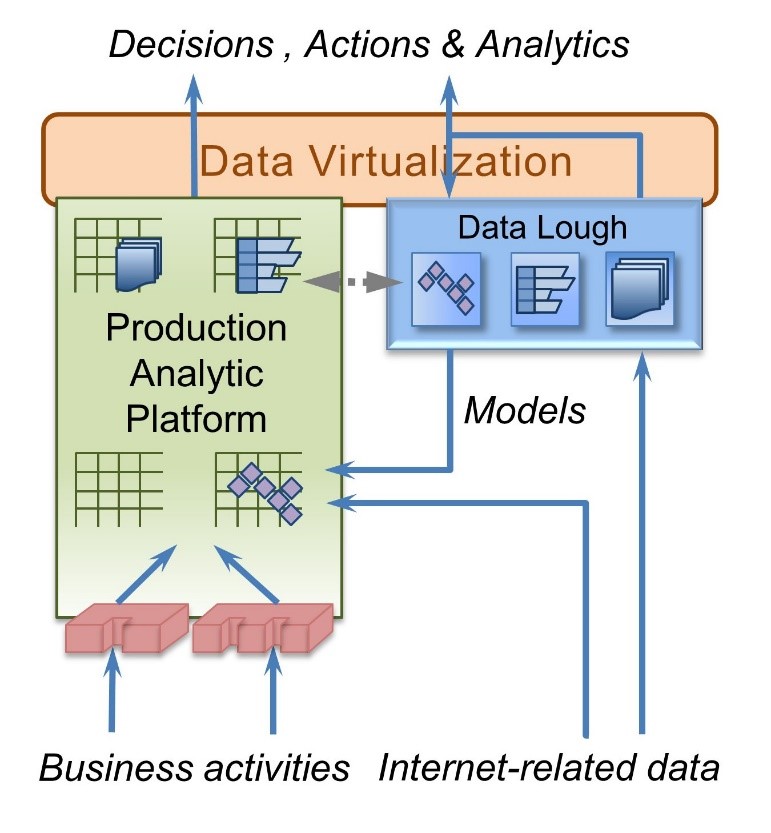
Figure 2 offers a new vision for the short to medium term future that positions the data lake/lough and begins to reunite operational and informational processing, taking advantage of technology advances in both relational and non-relational tooling.
On the left of the diagram, the data warehouse and some to-be-determined portion of the operational systems have been integrated into an extended relational environment called the Production Analytic Platform. This integration is facilitated by advances in relational database technology such as solid-state disks, in-memory databases, and multi-core parallel processing. In addition, relational databases increasingly support storage and processing of non-relational data formats, for example, JSON, Graph, etc. These extensions allow selected analytic tasks—those that demand reliability, availability, maintainability, and performance levels compatible with production use for daily operational decisions, as well as those that require access to traditional process mediated data—to be migrated from the data lough.
There is minimal change to the data lough itself. However, the feed of Internet-related data is split between that used in analysis and model generation, which continues to go to the data lough, and the real-time data that is used when models are put into production.
Where the data required for a particular analysis or decision is spread across the two environments, data virtualization allows joining of the required data at runtime.
Figure 2 does not claim to be a completely defined architectural vision for the evolution of the data warehouse. Rather it is offered as a starting point for discussion about how concepts such as data lakes and combined operational-informational systems can extend the traditional data warehouse architecture.
Just this year, I came across yet another mutation of the data warehouse / data lake concept. January 2020 has brought a new concept to the fore in the data management space. In a recent blog post, Ben Lorica (until recently, chief data scientist and Strata organizer at O’Reilly Media) and some senior names at Databricks report seeing “a new data management paradigm that emerged independently across many customers and use cases: the lakehouse.” (Lorica et al, 2020)
Simply put, a lakehouse is a cross between a data lake and a data warehouse. Its starting point is that data lakes are too loosely governed and structured for many business needs. As Lorica and his colleagues describe it, a lakehouse arises from “implementing similar data structures and data management features to those in a data warehouse, directly on the kind of low-cost storage used for data lakes.” At a more technical level, the concept hews closely to the functionality of the Databricks’ Delta Lake platform product. For more details on what it is and my opinion of its viability, see my TDWI Upside article (Devlin, 2020).
Conclusions
At over thirty years old, the data warehouse architecture has displayed remarkable longevity. Although the original architecture provided a strong foundation, much credit also goes to those who promoted it, built upon it, extended it, restructured it, and more. I mentioned some of the better known here: Inmon and Kimball, of course. Others were omitted for lack of space: Hans Peter Luhn’s original definition of business intelligence in 1958 and Howard Dresner’s reintroduction in the 1990s; Claudia Imhoff’s Corporate Information Factory also in the 1990s; Dan Linstedt’s Data Vault in the 2000s; and others to whom I apologize for their absence. Vendors such as Teradata and IBM, among others, contributed powerful technologies. And, of course, there are the thousands of architects in enterprises, consulting firms, and service providers who labored at the coal face of implementation—who corrected and added to the architecture in the process.
The data warehouse architecture lives on, extended with the concepts of analytics and data lakes. Artificial intelligence and the Internet of Things will drive further growth. The “Business unIntelligence” architecture shows the shape of the longer-term evolution, providing a template for all types of information in every possible business usage, as enterprises pursue extensive augmentation and automation of decision making. The data warehouse— as the repository of integrated, core business information—will continue to beat at the heart of current and future digital transformation.
Dr. Barry Devlin is among the foremost authorities on business insight and one of the founders of data warehousing, having published the first architectural paper in 1988. With over 30 years of IT experience, including 20 years with IBM as a Distinguished Engineer, he is a widely respected analyst, consultant, lecturer and author of the seminal book, “Data Warehouse—from Architecture to Implementation” and numerous White Papers. His 2013 book, “Business unIntelligence—Insight and Innovation beyond Analytics and Big Data” is available in both hardcopy and e-book formats. As founder and principal of 9sight Consulting (www.9sight.com), Barry provides strategic consulting and thought-leadership to buyers and vendors of BI solutions. He is continuously developing new architectural models for all aspects of decision-making and action-taking support. Now returned to Europe, Barry’s knowledge and expertise are in demand both locally and internationally.
Copyright Dr. Barry Devlin, Founder and Principal, 9sight Consulting